Can VAEs generate novel examples?
Dec 4, 2018· ,,,,·
0 min read
,,,,·
0 min read
Alican Bozkurt
Babak Esmaeili
Jennifer Dy
Dana H. Brooks
Jan-Willem van de Meent
Abstract
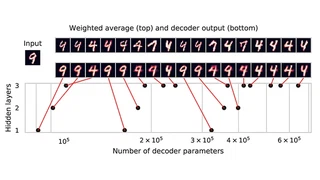
An implicit goal in works on deep generative models is that such models should be able to generate novel examples that were not previously seen in the training data. In this paper, we investigate to what extent this property holds for widely employed variational autoencoder (VAE) architectures. VAEs maximize a lower bound on the log marginal likelihood, which implies that they will in principle overfit the training data when provided with a sufficiently expressive decoder. In the limit of an infinite capacity decoder, the optimal generative model is a uniform mixture over the training data. More generally, an optimal decoder should output a weighted average over the examples in the training data, where the magnitude of the weights is determined by the proximity in the latent space. This leads to the hypothesis that, for a sufficiently high capacity encoder and decoder, the VAE decoder will perform nearest-neighbor matching according to the coordinates in the latent space. To test this hypothesis, we investigate generalization on the MNIST dataset. We consider both generalization to new examples of previously seen classes, and generalization to the classes that were withheld from the training set. In both cases, we find that reconstructions are closely approximated by nearest neighbors for higher-dimensional parameterizations. When generalizing to unseen classes however, lower-dimensional parameterizations offer a clear advantage.
Type
Publication
In Critiquing and Correcting Trends in Machine Learning Workshop at NIPS 2018

Authors
AI Scientist
I am an AI Scientist at Paige AI. I did my Ph.D. with Jennifer Dy, Dana Brooks, and Jan-Willem van de Meent at Northeastern University. My main research interests are machine learning with emphasis on probabilistic programming, deep neural networks, and their applications in biomedical image processing. I am one of the developers of Probabilistic Torch, a library for deep generative models that extends PyTorch. I am also one of the maintainers of the PyTorch distributions module.