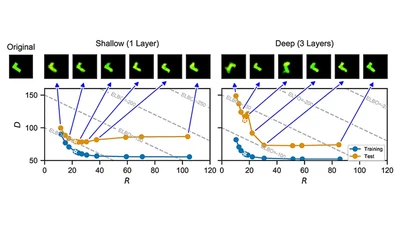
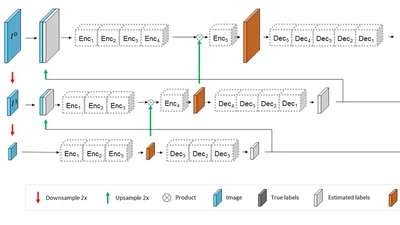
A Foundation Model for Clinical-Grade Computational Pathology and Rare Cancers Detection
The analysis of histopathology images with artificial intelligence aims to enable clinical decision support systems and precision medicine. The success of such applications depends …
eugene-vorontsov