Biography
I am a AI Scientist at Paige AI. I did my Ph.D. with Jennifer Dy, Dana Brooks, and Jan-Willem van de Meent at Northeastern University. My main research interests are machine learning with emphasis on probabilistic programming, deep neural networks, and their applications in biomedical image processing. I am one of the developers of Probabilistic Torch, a library for deep generative models that extends PyTorch. I am also one of the maintainers of the Pytorch distributions module.
Interests
- Probabilistic Programming
- Deep Learning
- Biomedical Image Processing
Education
-
PhD in Machine Learning, 2020
Northeastern University
-
MSc in Image Processing, 2013
Bilkent University
-
BSc in Electrical and Electronics Engineering, 2011
Bilkent University
Featured Publications
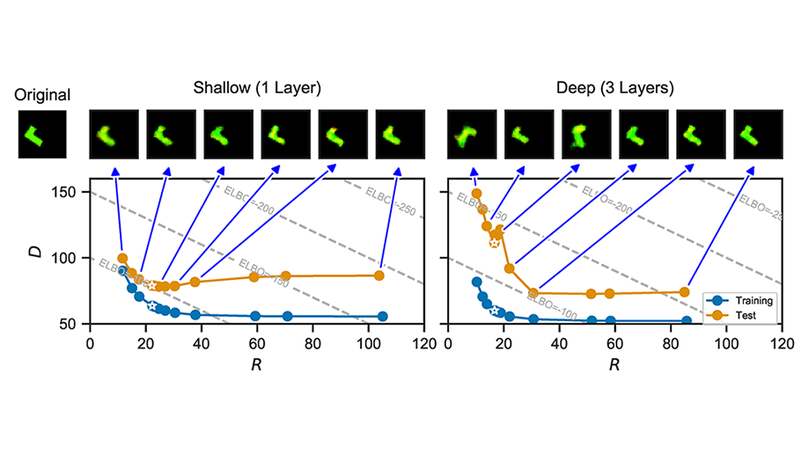
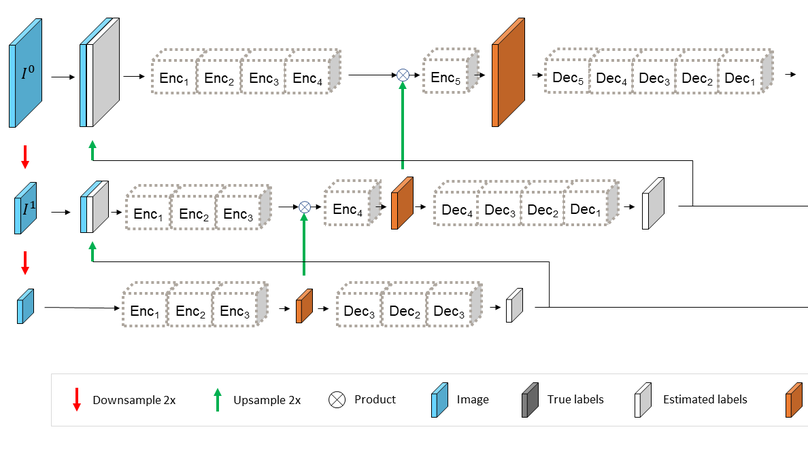
Recent Publications
Deep Representation Learning for Complex Medical Images.
Ph.D. Thesis,
2020.
Utilizing Machine Learning for Image Quality Assessment for Reflectance Confocal Microscopy.
In JID,
2019.
Facilitating the Adoption of Reflectance Confocal Microscopy (RCM) in Clinical Cancer Care Practice with Machine Learning.
In FAC Symposium,
2019.
Structured Disentagled Representations.
In AISTATS,
2019.
Contact
- alican@ece.neu.edu
- 805 Columbus Ave., Boston, MA 02130
- Northeastern University Interdisciplinary Science & Engineering Complex, Room 506